Research Note
Pokemon JEPA: Learning a Battle World Model
I trained a small Transformer on Pokemon Showdown replays to answer a simple question: does predicting the next state teach a model more about a game than predicting the final winner alone?
Intro
Pokemon Showdown is an online battle simulator where players test competitive Pokemon teams and every turn is recorded as a text log. A standard singles battle is a six-on-six game: each player has one active Pokemon, five on the bench, and chooses a move or switch every turn until one side has no usable Pokemon left.
That makes the modeling problem unusually clean. The battle log gives me a sequence of states and a final winner, but the cleanest label is also the most delayed one: somebody wins at the end. Pokemon is full of latent momentum: a full-health Pokemon can be useless into the wrong wall, a chipped setup sweeper can be decisive, and a missing sixth team slot can change the entire plan.
The experiment was to make the model learn those mechanics directly. I used a Joint-Embedding Predictive Architecture objective over structured battle states, then compared it against winner-only Transformers and tabular baselines. The punchline from the stricter replay-held-out run was not "winner accuracy went to the moon." It was more useful: the JEPA latent retained far more next-state information, cutting frozen next-HP probe MSE by 37-76% versus a winner-only latent across the replay budgets I tested.
Represent each battle as 12 object tokens: both active Pokemon plus both benches.
Train the latent state to predict next-turn HP movement, not only the final winner.
Reuse the same latent space for a masked-species teambuilder that fills a missing sixth slot.
Background
A standard supervised model can learn Pokemon correlations: high-usage species, HP advantage, faint counts, and obvious matchups. That is already useful. The failure mode is that correlations can masquerade as understanding. If the model only sees final winners, it can be right for shallow reasons and brittle in states where momentum is hidden.
JEPA changes the pressure on the representation. Instead of asking only who eventually won?, it also asks what should the next board look like? For this environment, I used next-turn HP as the predictive target. It is not a complete simulator, but it is a dense proxy for damage, recovery, switching pressure, setup, walls, and tempo.

Model
The parser converts each replay turn into a fixed sequence of 12 Pokemon objects: P1's active slot and bench, then P2's active slot and bench. The lightweight study used species, HP, and status. The teambuilder extension adds sparse item and move channels, plus a masked-species head for asking, "what should fill this missing slot?"
[Gen 9] PU Pokemon Showdown logs
within-replay next-state pairs
six Pokemon per side
12GB VRAM; minutes per pruning run

Input
A structured board state: species embeddings, normalized HP, status, and in the teambuilder model, item and move embeddings.
Latent
A compact Transformer representation over all 12 Pokemon, allowing active threats, bench answers, and opponent structure to interact through self-attention.
Objectives
Mean-squared error on next-turn HP, binary cross-entropy on winner, and masked species prediction for team completion.
Concretely, each training example is a pair: the current board state and the next board's HP vector. The model is not asked to imitate a move directly. It has to compress the current situation into a latent state that is predictive of what the board will look like after the next turn.

Results
The main comparison is deliberately small: 991 parsed public [Gen 9] PU replays from the Pokemon Showdown replays dataset, 20,831 within-replay turn transitions after filtering, and local training on a GTX 1080 Ti. The goal was not to claim a universal Pokemon engine. It was to test whether a dynamics objective changes what a compact model learns. The code, generated figures, and lightweight result artifacts are available in the public project repo.
Result 1
The dynamics signal is the clean win
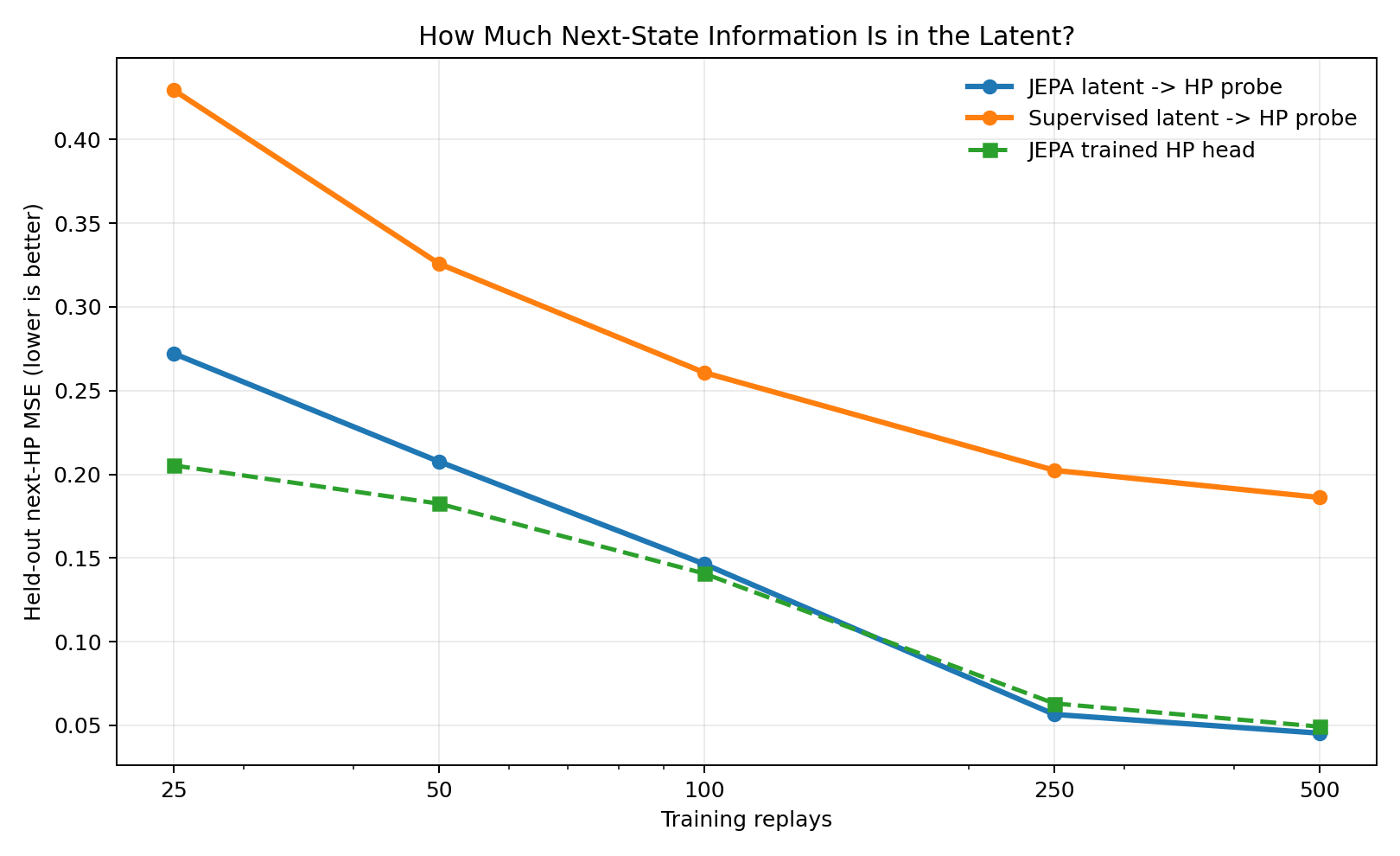
I freeze the trained encoders, fit a small ridge probe from latent state to next-turn HP, and evaluate on held-out replays. Lower MSE means the latent retained more information about how the board changes.
The JEPA latent is consistently easier to decode into the next HP vector than the winner-only latent. That is the core empirical claim: the objective changes what the representation keeps.
Result 2
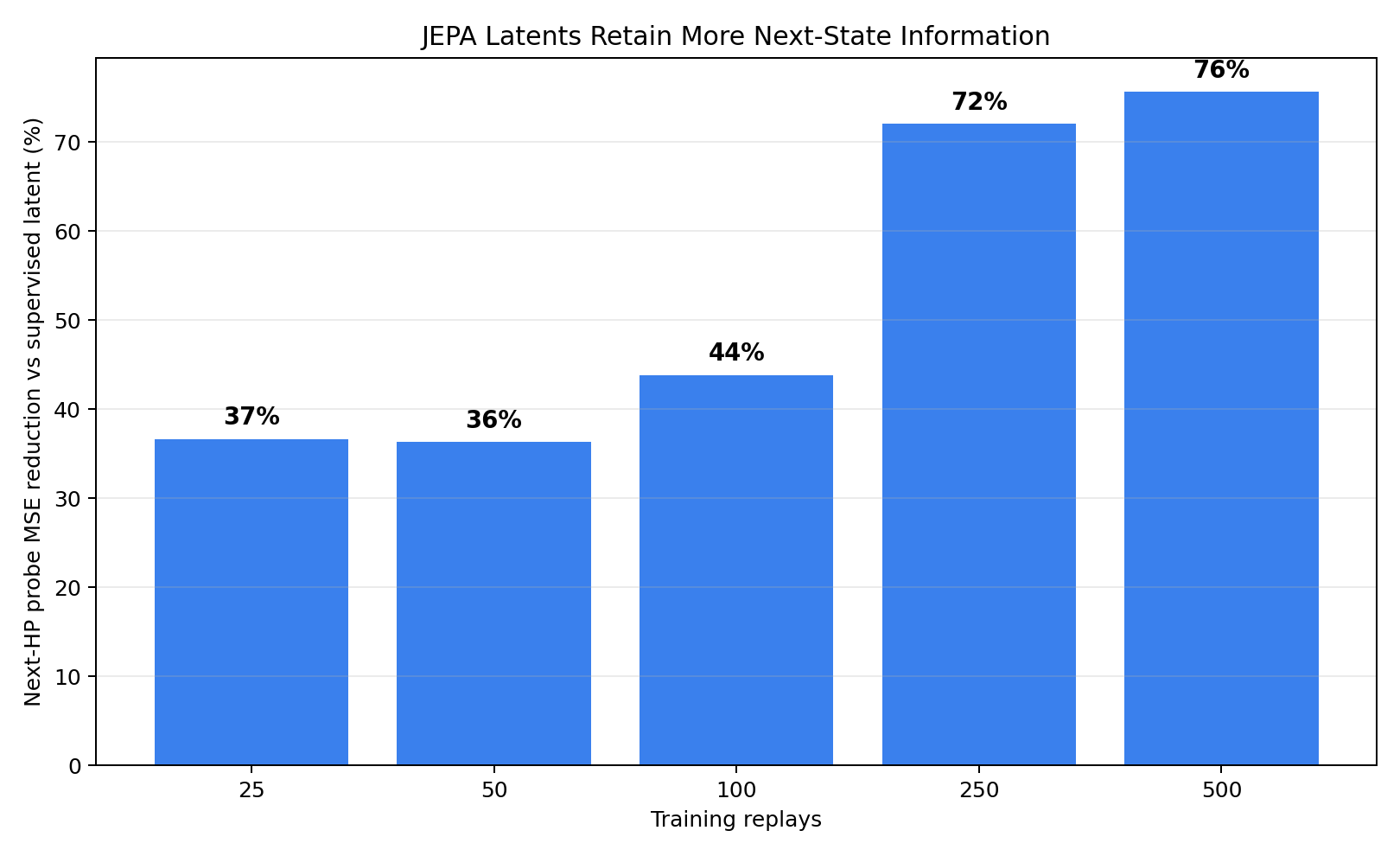
The relative gap grows with more data
This chart turns the previous curve into a percent reduction versus the supervised latent. At 25-100 training replays the advantage is already visible; by 500 replays, the JEPA latent has 76% lower next-HP probe error.
Winner accuracy remains noisy in this small replay-held-out setup, so this is the better result to lead with: the world-model objective makes the state representation more predictive of the next state.
| Metric | 25 Replays | 100 Replays | 500 Replays | Interpretation |
|---|---|---|---|---|
| JEPA latent -> next-HP probe MSE | 0.272 | 0.146 | 0.045 | Lower is better; frozen latent, ridge readout |
| Supervised latent -> next-HP probe MSE | 0.429 | 0.261 | 0.186 | Same encoder shape, trained only on winner labels |
| JEPA MSE reduction vs supervised latent | 37% | 44% | 76% | How much next-state information the JEPA objective preserved |
| Winner-head accuracy | 52.2% | 50.4% | 55.2% | Noisy under replay-held-out evaluation; not the main claim |
This is why the results section should lead with dynamics, not a two-bar winner-accuracy chart. The winner head is noisy under replay-held-out evaluation, while the frozen-latent probe shows the effect of the objective directly: the JEPA representation remembers much more about how HP will move next.
Visual Probe
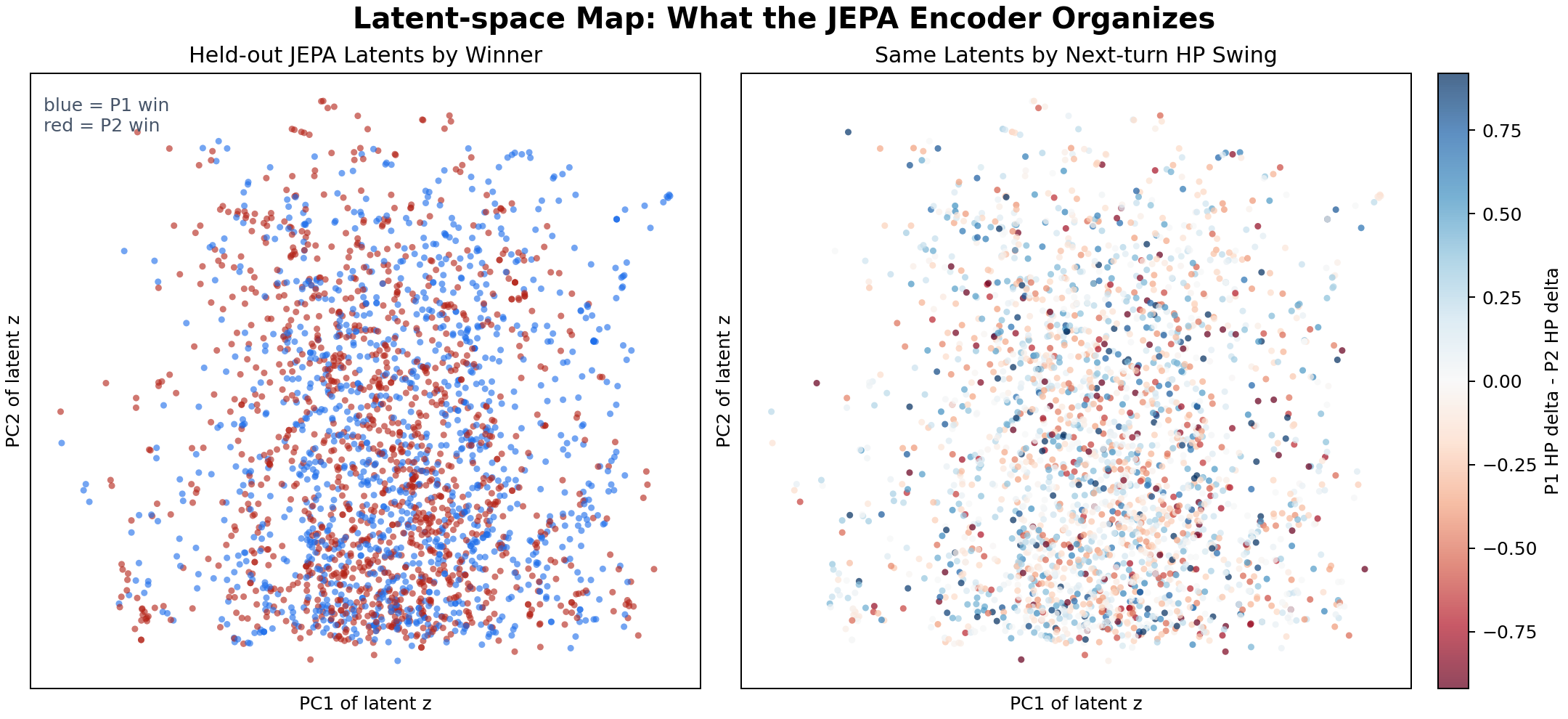
Latent-space map
This is an interpretability check, not the headline metric. I take held-out battle states, encode each one into a JEPA latent vector, and project those vectors to 2D with PCA. The two panels show the exact same dots; only the color changes.
- The left coloring asks whether nearby latent states tend to share the same eventual winner.
- The right coloring asks whether nearby latent states also share similar next-turn HP movement.
- If the representation were just species lookup noise, both colorings would look spatially random.
The map is intentionally modest: there are no clean separable clusters, and PCA is lossy. The useful signal is that the same latent geometry carries both strategic outcome information and tactical HP-delta information, matching what the frozen dynamics probe measured quantitatively.
Visual Probe
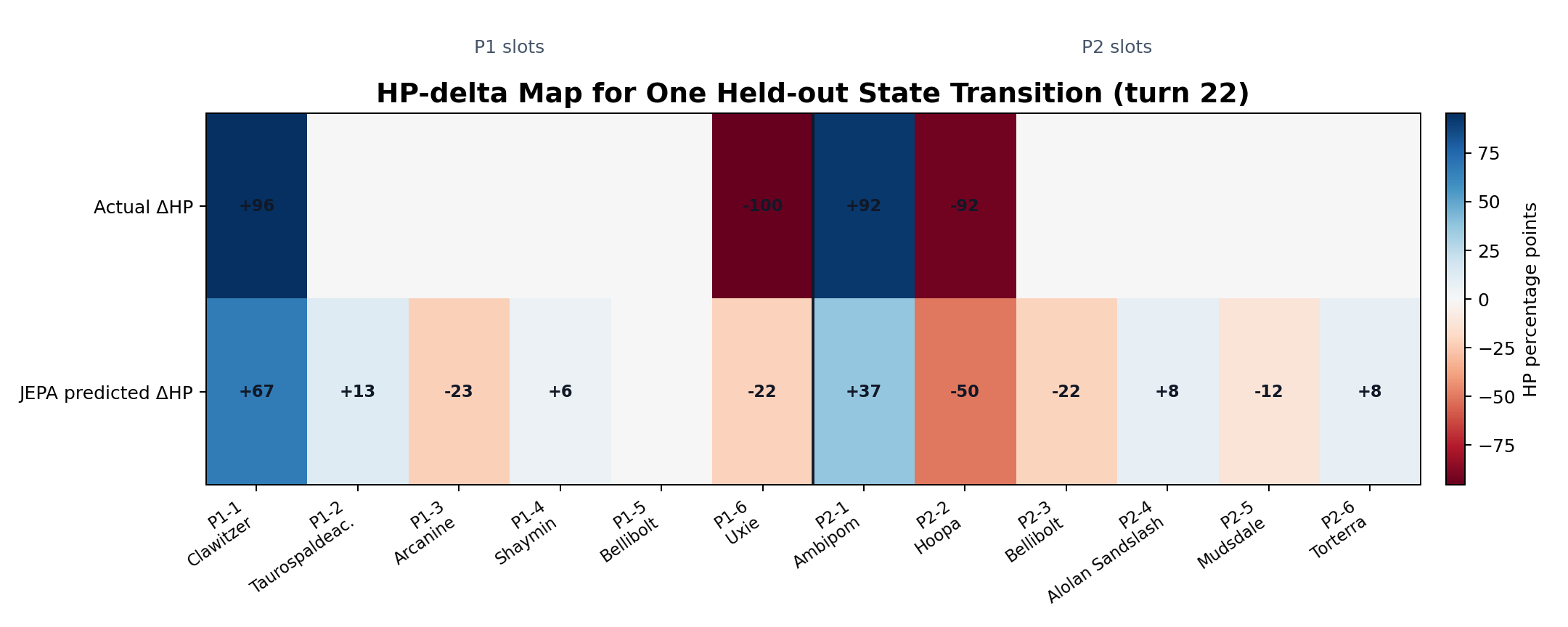
HP-delta map
This shows one high-movement held-out transition, slot by slot. The top row is the actual next-state HP delta; the bottom row is the JEPA HP head's prediction.
Because active slots can change during switches, this is a next-state slot target, not a pure same-Pokemon damage log. The useful question is whether the model has learned where large changes are likely to happen.
Examples
The most useful way to read the examples is as a sequence. First, the JEPA model evaluates battle states more like a forward simulation than a popularity score. Then the same representation transfers into teambuilding, where it fills missing roles instead of merely suggesting common Pokemon.
State Evaluation
Dynamics Example 1
A healthy team that is already losing
The label-only model sees six healthy Pokemon and several recognizable attackers. The JEPA model sees a stalled damage trajectory.
P1 board
 Salazzle 100% special pressure
Salazzle 100% special pressure  Bellibolt 100% bulky special
Bellibolt 100% bulky special  Cryogonal 100%
Cryogonal 100%  Grimmsnarl 100%
Grimmsnarl 100%  Paldean Tauros Aqua 100%
Paldean Tauros Aqua 100%  Rotom Mow 100%
Rotom Mow 100% P2 board
 Froslass 100%
Froslass 100%  Coalossal 100% Salazzle answer
Coalossal 100% Salazzle answer  Scream Tail 100% special wall Grimmsnarl 100%
Scream Tail 100% special wall Grimmsnarl 100%  Dusknoir 100%
Dusknoir 100%  Clawitzer 100%
Clawitzer 100% - Surface read: Salazzle, Bellibolt, and Rotom-Mow look like enough special pressure to carry P1.
- World-model read: Scream Tail absorbs that pressure, Coalossal turns Salazzle into tempo, and P1 lacks a physical breaker that changes the HP trajectory.
- Why it matters: the JEPA objective rewards representations that notice future board movement, so it can call a collapse before the winner label becomes obvious.
Dynamics Example 2
The head-count trap
P1 appears to have material left. The real game is about whether anything can survive the boosted Scyther sequence.
P1 board
 Alcremie 100%
Alcremie 100%  Gastrodon East 0% fainted Coalossal 0% fainted Rotom Mow 28% chipped
Gastrodon East 0% fainted Coalossal 0% fainted Rotom Mow 28% chipped  Paldean Tauros Blaze 45% chipped
Paldean Tauros Blaze 45% chipped  Hisuian Braviary 100%
Hisuian Braviary 100% P2 board
 Scyther 77% Swords Dance + Trailblaze
Scyther 77% Swords Dance + Trailblaze  Hattrem 3%
Hattrem 3%  Bombirdier 100%
Bombirdier 100%  Arcanine 64%
Arcanine 64%  Hisuian Decidueye 100%
Hisuian Decidueye 100%  Rhydon 100%
Rhydon 100% - Surface read: P1 still has four visible bodies and two untouched Pokemon, so the supervised model remains bullish.
- World-model read: Scyther has already converted setup into speed and damage. The next few turns are not independent; they are a sweep line.
- Why it matters: predicting HP deltas forces the latent to encode momentum, not just count remaining Pokemon.
Team Completion
Teambuilder Example 1
Finishing the sand core
Once the latent understands weather mechanics, the missing sixth slot stops being a popularity contest.
Five-slot P1 core
 Hippopotas 100% sand setter
Hippopotas 100% sand setter  Sandaconda 100%
Sandaconda 100%  Sandslash 100%
Sandslash 100%  Lycanroc 100%
Lycanroc 100%  Quaxwell 100%
Quaxwell 100% Opponent context
 Ambipom 100%
Ambipom 100%  Uxie 100%
Uxie 100%  Tatsugiri 100%
Tatsugiri 100%  Shaymin 100% Paldean Tauros Blaze 100%
Shaymin 100% Paldean Tauros Blaze 100%  Florges 100%
Florges 100%  Grumpig
Grumpig 44.1% predicted P1 win
 Houndstone
Houndstone 77.6% predicted P1 win
+33.5 pts- Supervised suggestion: Grumpig is a plausible generic utility pick, but it does not amplify the existing plan.
- JEPA suggestion: Houndstone completes the sand offense. Sand Stream plus Sand Rush changes the speed landscape, which changes the win trajectory.
- Modeling win: the same latent that predicts turn movement also recognizes team-level synergy.
Teambuilder Example 2
Patching the defensive hole
Adding more firepower to a glass cannon team looks attractive until the opponent has a setup line.
Five-slot P1 core
Lycanroc 88% Focus Sash + Stealth Rock  Goodra 37% chipped pivot
Goodra 37% chipped pivot  Minior 100%
Minior 100%  Zoroark 100%
Zoroark 100%  Alolan Sandslash 100%
Alolan Sandslash 100% Opponent context
 Snorlax 38% Belly Drum threat
Snorlax 38% Belly Drum threat  Exeggutor 100%
Exeggutor 100%  Carbink 100%
Carbink 100%  Galarian Articuno 100% Dusknoir 0% Trick Room revealed Grimmsnarl 100% Arcanine
Galarian Articuno 100% Dusknoir 0% Trick Room revealed Grimmsnarl 100% Arcanine 0.8% predicted P1 win
Uxie 28.5% predicted P1 win
+27.7 pts- Supervised suggestion: Arcanine adds another attacker to an already fragile core.
- JEPA suggestion: Uxie gives the team a bulky utility pivot and a way to disrupt the Snorlax / Articuno-G endgame.
- Modeling win: the latent does not merely ask which Pokemon is common; it asks which missing role changes the future state.
Discussion
The result changed my view of the problem. The useful artifact is not a magically better winner classifier; under a replay-held-out split, that signal is noisy and easy to overfit. The useful artifact is a latent state that can be reused: it preserves next-state information, supports masked team completion, and produces tactical disagreements that are explainable in Pokemon terms.
The current system is still a proof of concept. It uses only 1,000 Gen 9 PU replays, its move and item channels are sparse, and next-turn HP is only a proxy for battle quality. The next steps are clear: scale to larger Random Battles corpora, add richer move/item and weather/terrain features, probe the latent space for interpretable clusters, and connect the state model to action selection rather than only evaluation and teambuilding.
References
- Pokemon Showdown: the online battle simulator used as the replay source.
- Pokemon Showdown GitHub repository: simulator implementation and protocol context.
- milkkarten/pokemon-showdown-replays-merged: Hugging Face dataset used for the cached replay sample.
- pokemon-jepa-world-models: public code, figures, and lightweight result artifacts for this experiment.
- Assran et al., Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture, arXiv:2301.08243.
- LeCun, A Path Towards Autonomous Machine Intelligence, position paper introducing JEPA-style predictive world-model framing.